作为中华文明的重要载体,古汉字在数千年演变过程中形成了甲骨文、金文、篆书、隶书等多样化形态,其结构特征与现代汉字存在显著差异。这些文字广泛留存于古籍文献、碑刻拓片、书法作品等载体中,其准确识别往往需要深厚的古文字学专业知识。随着深度学习技术的发展,卷积神经网络(CNN)与视觉Transformer(ViT)被广泛应用于各类汉字识别。然而现有研究多集中于单一字体或载体类型汉字识别,如针对甲骨文或简牍帛书的专项识别。这种研究范式存在明显局限性:一方面难以适应不同历史时期、不同地域古汉字在结构和形态上的巨大差异;另一方面无法满足实际应用场景中多类型汉字混合识别、多载体联合处理的现实需求。同时,自然场景下的古汉字识别还面临三大核心难题:一是字符类型复杂多样,涵盖不同历史时期的多种汉字;二是待识别字符数量庞大,系统性处理难度高;三是应用场景分布广泛且环境复杂。这些因素共同构成了制约当前古汉字识别研究发展的关键瓶颈,亟需通过构建大规模多类型汉字数据集和开发通用识别模型来突破。

6月19日,Nature旗下期刊npjheritagescience在线发表我校人文学院数字人文专业博士生王钊江(指导教师吴夏平教授)与湖州师范学院、华南理工大学联合开展的一项针对多样化应用场景古汉字识别的重要成果,题为“HUNet: hierarchical universal network for multi-type ancient Chinese character recognition”(https://www.nature.com/articles/s40494-025-01813-9)。论文提出了一种面向中国八体汉字识别的轻量化网络模型。该模型针对书法挂画、碑刻石刻、楹联匾额等多样化应用场景,实现了对古代汉字的精准高效识别。通过创新的网络架构设计,模型在保证识别准确率的同时显著降低了计算复杂度,具备良好的跨平台适配性,可灵活部署于各类终端设备。

论文基于《通用规范汉字表》构建了超900万样本量的Multi-Type Ancient Chinese Character Recognition(MTACCR)数据集。MTACCR数据集包含多种类型汉字图像,包括原始扫描图像和经过预处理的二值化字形图像。与现有相关数据集相比,MTACCR数据集在字符数量、古汉字类型、数据规模和图像多样性方面均实现了显著扩展和丰富。为了满足不同应用场景下古汉字的快速高效识别,论文进一步提出Hierarchical Universal Network(HUNet)。HUNet采用层次化网络架构,通过不同阶段关注汉字的局部形状和几何特征、关键位置和笔画关系、空间结构关系,实现了模型参数利用效率的提升,使得模型网络在保持低参数量和高吞吐量的同时实现了较高的识别性能。
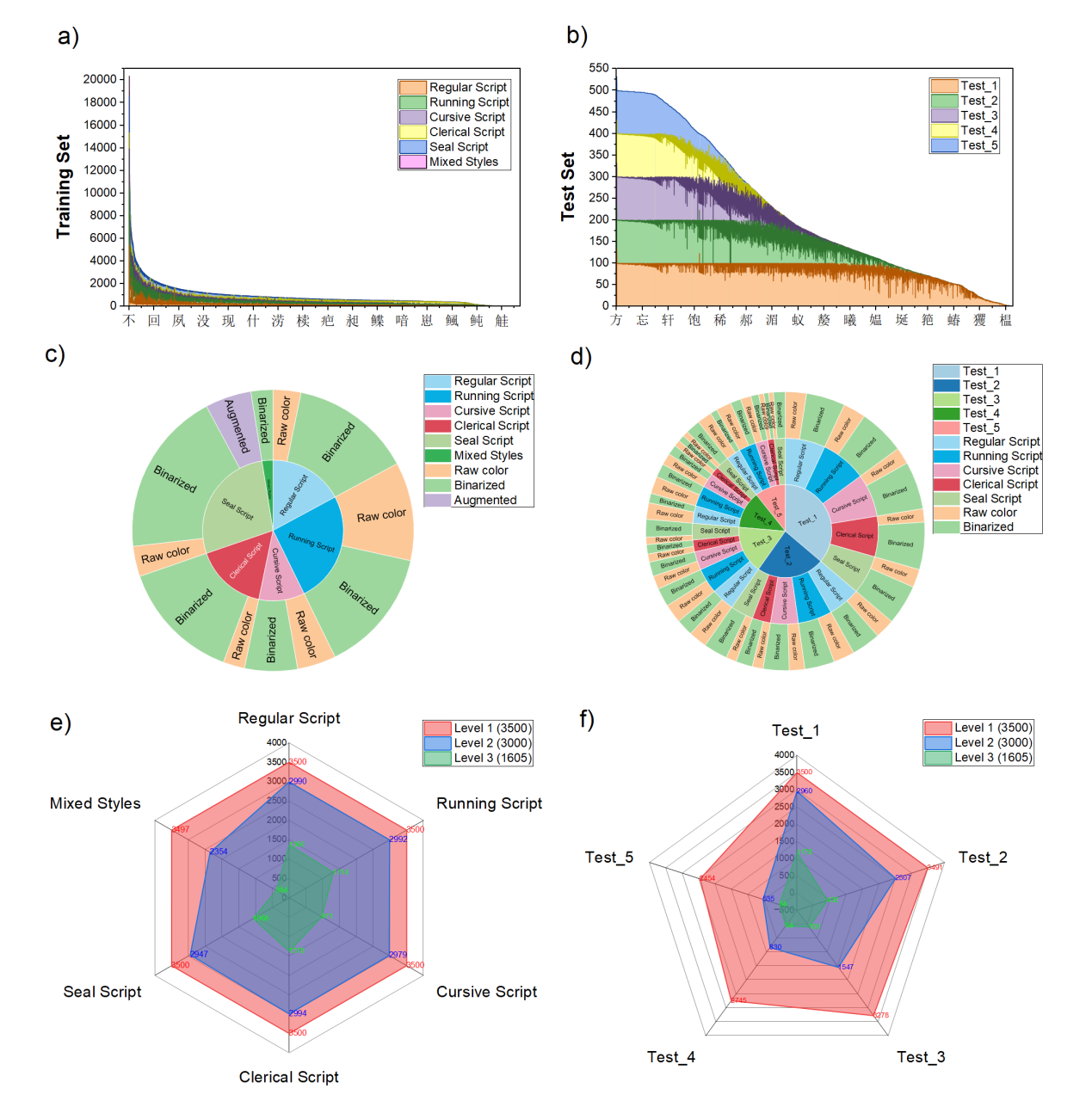
MTACCR数据集统计
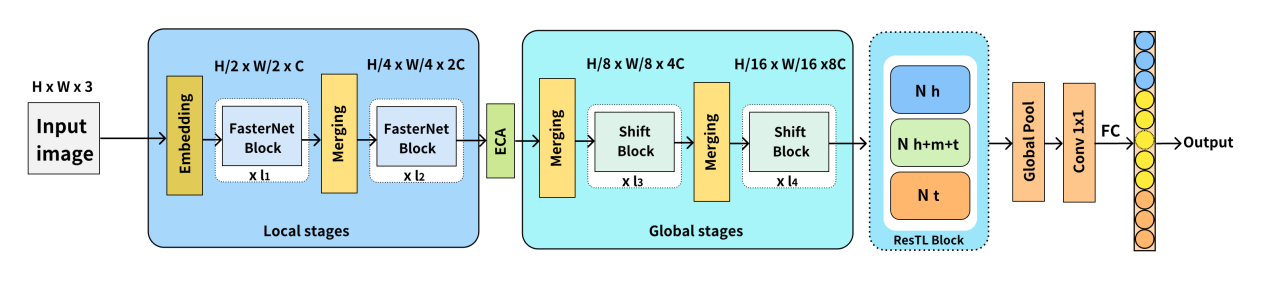
HUNet宏观网络架构
实验结果表明,HUNet模型在MTACCR数据集和多场景古汉字识别(MACR)数据集上的测试性能表现优异。与其他参与评估的高效CNNs和ViTs模型相比,HUNet在参数量相当的情况下实现了更高的识别性能,或在识别性能相当的情况下保持了更低的参数量,同时维持了较高的计算吞吐量。在MTACCR Test_1测试集上(包含60万测试样本),HUNet_48的Top-1准确率达到94.23%。在MACR测试集上,使用MTACCR训练的HUNet模型的Top-1准确率提升了9.64%。此外,HUNet还可有效扩展到非汉字古代文本识别任务,在DeepLontar和ALPUB_v2两个数据集上表现出一定的竞争优势。
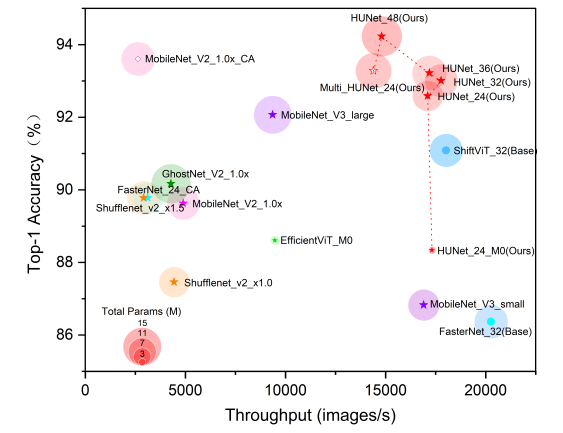
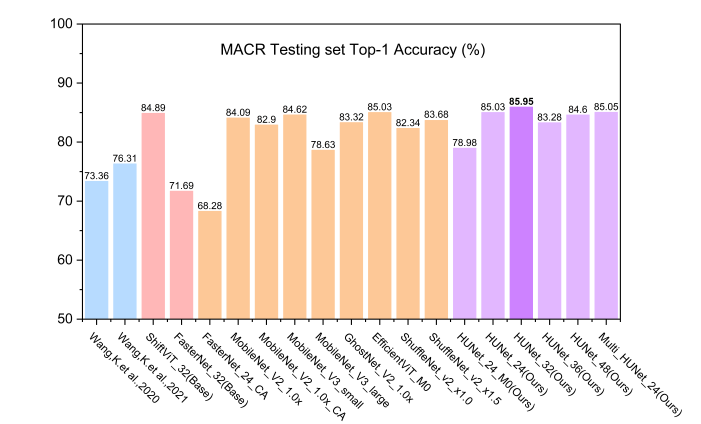
HUNet与其它高效模型性能对比
在论文提出的轻量化网络模型基础上,研究团队进一步开发了智能云端古汉字识别小程序。该小程序融合场景文本检测算法,能够实现对多样化场景中各类古汉字的实时精准识别,为用户提供便捷高效的古文字识别服务。论文开源地址:https://github.com/1602353775/HUNet

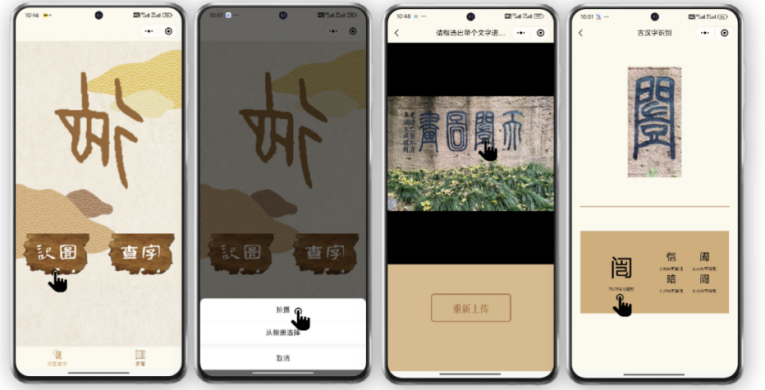
智能云端古汉字识别小程序
上海师范大学人文学院聚焦服务国家重大战略,以深化新文科建设内涵为切入点,高度重视数字人文学科建设。2020年成立数字人文研究中心,2021年获批上海市“数字人文资源建设与研究”重点创新团队,2022年获批数字人文专业博士点,2023年开始招收数字人文专业博士生。近年来,团队已出版“数字人文教材系列”“数字人文研究丛书”等多种著作,在国内外重要学术刊物发表论文多篇,为数字人文专业人才培养夯实了基础。
(供稿、图片:人文学院)

